Benchmarking procedure
Benchmarking and Publishing in a Diverse Grid Site
S Jones, R Fay, J Bland
University of Liverpool 30th August 2016
Contents
Introduction
Benchmarking is an estimate of the power of a system. Accounting, which depends on benchmarking, is an estimate of the effort used (i.e. work done) running jobs on the system. Publishing, in this context, is the act of transmitting benchmark values to interested parties. We'll discuss how these aspects are managed in an integrated fashion at a particular site. The intent is to go over the key aspects for the benefit of all and to try to create a shared view on how it should be done.
The Liverpool grid site is used as an example. It has become quite diverse, and the Liverpool admin staff have used a several techniques to manage the diversity. The site is heterogeneous at several levels: it has a range of different worker-node hardware, running over over three different clustering technologies; CREAM/Torque, ARC/Condor, and VAC. This article will cover the tricks of the trade for getting the benchmarking and accounting publishing right across the spread. The article does not cover the use of the glite-CLUSTER node type, which aggregates the publishing information from several resources to model a heterogeneous cluster.
We discuss hardware benchmarking (which is nearly the same for all clustering technologies), and the requirements for publishing accounting information and cluster power. We'll also show how we have used a simple database tool to manage the cluster layout and do the necessary arithmetic for a diversity of cluster technology on YAIM configuration for CREAM/Torque, and configuration without YAIM for the other technologies.
These techniques comprise an integrated approach for managing multiple clusters of various technologies each containing diverse hardware. Hopefully, these techniques for dealing with diversity will provide a framework that can be used directly at other sites, or adapted to suit different but comparable scenarios.
This work is based on the GridPP Publishing tutorial[8], which explicitly lays out how to do these tasks by hand, if you wish.
What are we trying to measure?
We are trying to measure the power at the site, and how much work we do with that power, using a benchmark. A benchmark is a standard reference against which things may be compared. The WLCG lays down the requirements for benchmarking, and they have communicated to GridPP that the current benchmark is HEPSPEC06 (HS06), in 32 bit mode[1][2] running on an SL6 system. The GLUE schemas of the BDII provide support for publishing the required benchmark data.
Units
Accounting and power figures are now generally in HS06. However, values are sometimes transmitted to the outside world in SpecInt2K (SI2K). For compatibility, it was decided that SI2K would be redefined to be equal to 1/250th of a HS06, and the values would then be transmitted in the new SI2K units (which might be called "bogoSpecInt2k" if I were being rigorous.) HS06 values are converted to this SI2K by timesing them by 250 prior to transmission (as a corollary to this, there are 4 x HS06 in one KiloSpecInt2k (KSI2K), i.e. 1000/250.) Accounting, in this article, is generally in HEPSPEC06 HOURS (HS06.h) or HEPSPEC06 SECONDS (HS06.s) , similar to the convention for expressing electrical power (i.e. kW.h). These values may be prefixed by a k, or m or whatever, or postfixed by .h, .s or whatever depending on the magnitude or time period in question.
Hardware benchmarking
Many sites have documented their results in a table of HEPSPEC06 results[2], so that others can use the settings without repeating the benchmark process. However, results depend on slots (i.e. logical cpus) utilised, and hardware variations can further affect the outcomes. So unless you are lucky, it might be best to run your own benchmarks.
What is HEPSPEC06, and how do I use it
The HEPSPECO6 benchmark is built 'on top of' another benchmark, SPEC06[5]. That part (product filename is spec2006-1.2.tar.gz) requires a licence. The part[6], which is actually the config files, (product filename is spec2k6-2.24.tar.gz) is free to download here:
http://w3.hepix.org/benchmarking/how_to_run_hs06.html#configuration-files-and-script
Details for running the suite are on HEPiX web[6]. Whatever the clustering technology, the HW benchmarking process is the same. The standard steps[3][6] are:
- License the SPEC2006 benchmark suite, to obtain spec2006-1.2.tar.gz
- Download the free spec2k6-2.24.tar.gz
- Drain a system of the type you wish to benchmark.
- Make sure the system has these rpms:
- gcc-c++
- glibc-devel.i686
- compat-libstdc++-33.i686
- libstdc++.i686
- libstdc++-devel.i686
- compat-libstdc++-296.i686 (not necessary on CentOS7.6)
- Make working directory and put the products in it.
- Untar spec2006-1.2.tar.gz then spec2k6-2.24.tar.gz
- On CentOS7, add to the CXX line in linux32-gcc_cern.cfg
-include cstddef -std=c++11
- Run HEPSPEC06 on your cpus, in 32 bit mode[2] using the the OS you have in production.
- View the results with the runspec-result-sum.sh script.
- Publish the values, to be discussed.
However, at Liverpool we have made small changes to this procedure that are discussed in the next section. The changes allow us to maximise work throughput by choosing the best number of slots per node.
Choosing the best number of slots
Should slots equal hyperthreads? Probably not - the best number of slots to chose may be less than the number of hyperthreads. But first, lets nail the terminology.
- Job slots are allotted to worker nodes, so we wish to measure the throughput of a worker node when it is at maximum load.
- Each worker node system is composed of 1..M CPUs.
- A CPU contains 1..N cores and each core can run 1..2 hyperthreads.
However, making slots equal to hyperthreads does not necessarily maximise throughput. Experiments (see below) show that it is sometimes necessary to choose a number of slots that is higher than the number of cores but slightly lower than hyperthreads. The reason for this could be contention. Anyway, there is often negligible if any increase in overall throughput when approaching slots == hyperthreads. In summary, you can get practically the same throughput with slots < hyperthreads AND you won’t need as much memory in each node, because it will run fewer jobs but each job will run more efficiently.
So we need to change the benchmark procedures to allow us to vary the number of slots. The standard script (runspec.sh) that comes with the products assumes you want to use slots == hyperthreads, i.e. it runs as many instances of the benchmark as hyperthreads in the node. At Liverpool, we have made small changes to the benchmark script to allow slots to be set by the user as a parameter. The new file is called runspec32-N.sh, and we give instructions how to use it in an accompanying text file[4]. With this modification, the procedure for choosing the number of slots is as follows.
- For each type of node at your site, run an instance of the benchmark for every number between cores and hyperthreads, to cover the whole area.
- Compare all the results and select the number of benchmark instances that gives the maximum applied computing power overall from these scenarios and use that as the number of slots for this node type, i.e. chose the sweet spot.
- Where the sweet spot is flat (e.g. practically the same overall throughput is obtained with 14, 15 or 16 instances on a 16 hyperthread node), choose the lowest, because this combines the highest throughput with the most memory available per job.
- And, in any-case, always chose a number that at least provides adequate memory per job.
These rules maximise use of cpu power in a fully loaded cluster while giving adequate memory for each job, but there are some other concerns that are outside the scope this is talk. These rules pay no heed to multicore considerations in this rule: sites may wish to chose a slot count that is a multiple of 8 in a cluster that runs multicore jobs; this would allow the node to be maximally utilised even if there are no queued single-core jobs. Other constraints, such as bandwidth or data retrieval rates may also be factors.
Also, it's quite possible that the best number of slots for a certain type of node used with one technology, e.g. CREAM/Torque, is not the best number of slots for the same type of node when used with another technology, e.g. VAC. The context of VAC VMs takes some RAM. At Liverpool, we found that machines were going into swap with a E5620 using 12 slots, which does not happen on CREAM/Torque. Thus we back that off and put 10 slots on those VAC nodes. There is very little practical difference to the throughput because we are close to the top of the curve anyway, see Figure 2 below.
The following plots, which are not definitive at our site, serve to verify these observations. Initially, there is only a slight plateau near max slots; on more advanced hardware with more cores, the plateau gets gradually more apparent. However, each run does not yield exactly the same results - spreads of variation of between 1% to 3% are quite typical, indicating the noise limits of this benchmark.
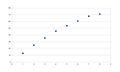
Figure 1: L5420 - 8 hyperthreads; no plateau
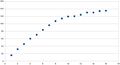
Figure 2: E5620 - 16 hyperthreads; plateau emerging
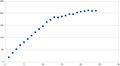
Figure 3: X5650 - 24 hyperthreads; plateau and drop off
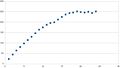
Figure 4: E52630 v2 - 24 hyperthreads; plateau, drop off and recovery
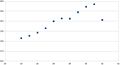
Figure 5 - E52630-v3 - 32 hyperthreads; last point is outlier
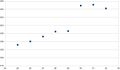
Figure 6 - E52630-v3 - Retry the peak. Weird results. 5% noise...






The site layout database
So, following the procedures up to now, you will have run the benchmarks over the whole area for each worker-node hardware type at your site and you have decided on the slots per node for each type. Next we'll discuss a way to manage a site layout, whereby the work-nodes are allocated to various types of cluster technology, namely CREAM/Torque, ARC/Condor or VAC. The eventual plan could be to expand this so that workernodes can be seamlessly reallocated to different technology baselines on an as-needed basis, making workernodes technologically agnostic.
I expect most sites will have their own ways (possibly ad hoc) of tracking this information; that's fine. I'll show how we do the configuration using the Liverpool tools, and how to do it manually if you want to use your own arrangements for handling the layout.
To make this real, we use a model of the site that I'll refer to as the Site Layout Database. The model is the simplest that can do the job, and it uses three entities (tables) arranged as per this relationship diagram.

The CLUSTER entity gives a name and description to each cluster. At our site, it has three entries for CREAM/Torque, ARC/Condor and VAC. The other tables define sets of nodes and types of nodes respectively, and these nodes are assigned to the clusters. The CLUSTER and NODETYPE entities relate to each other via a many-to-many relationship (a particular cluster can have many different types of node, and a particular type of node can occur in many clusters) with a resolution table, NODESET, that maps what nodes of what type belong to any specific cluster. To keep things simple, we don't model node ranges or physical locations. Instead, the “nodeCount” attribute lets us model sets of nodes. By convention, a clue to the physical location is given in the nodeSetName attribute, which is indicative of the rack location where sets of nodes reside (e.g. 23p1 represents nodes 1 to 10 in rack 23, while 23p2 represents nodes 11 to 20 etc.) With this model, we can have heterogeneous racks.
We maintain the current layout of our site in this database. The primary output of the database is a report which gives us the benchmark figures for entry into our publishing system, which will be discussed in the next sections.
Note: we used spreadsheets for this before we put the database together.
Cluster Benchmark Publishing Configuration
In this section, I'll show how we map the values from the site layout database into the configurations of each cluster type, so that the publishing works. I'll use the report from our site, taking the sections from each cluster and illustrating where they fit in the config. I'll also show briefly how to do this by hand, without any site layout database.
General site information
The first section in the report is general, and shows the details for each node type used in the entire site.
Node types:
Name, CPUs, Slots, HS06 (Slot), RAM (Slot), Scale factor
BASELINE, 0, 0, 10.00, 0.00, 0.0000
L5530, 2, 7, 12.34, 3.50, 1.2340
L5420, 2, 8, 8.90, 2.00, 0.8900
E5620, 2, 12, 10.63, 2.00, 1.0633
X5650, 2, 24, 8.66, 2.08, 0.8660
E5-2630, 2, 23, 11.28, 2.17, 1.1280
E5-2630V3, 2, 32, 11.07, 4.12, 1.1070
E5620-VAC, 2, 10, 12.05, 2.40, 1.2050
BASELINE is special. For the other node types, by convention I use the name of the CPU as the unique node type name; one could have different node types with the same CPU if (for example) one type had (say) less RAM. In that case, you could by convention use names such as L5530LOWMEM, or whatever you like. Most of the other fields are fairly explanatory, but for completeness:
- CPUs: Number of CPUs in each node of that node type.
- SLOTS: Number of slots chosen for each node of that node type.
- HS06 (Slot): HEPSPEC06 per slot
- RAM (Slot): RAM per slot
- Scale Factor: Used to scale run times in heterogeneous clusters.
At this point, some words are needed on BASELINE and Scale factor. The APEL accounting system accepts job run time data from sites, i.e. how long each job ran for. It also accepts a figure representing the power of the node the job ran on. This allows the computing power spent by the job to be computed by multiplying time by power, giving HS06.s
This would be fine for a site that has one node type. But sites have multiple node types, with different powers. Thus the site layout database must contain one NODETYPE called BASELINE. This is an abstract NODETYPE - it is not necessary for real nodes like this to exist. The job run time data from jobs that ran on real nodes is scaled (made longer or shorter) commensurately to how powerful the real node is compared to the abstract BASELINE node. An example is useful to show this. At our site, the BASELINE node type has a power of 10 HEPSPEC06. We tell the accounting system what BASELINE is, and the accounting system will therefore assume that each job ran on a node with 10 HEPSPEC06s of power. An L5530 actually gives 12.34 HS06 per slot. Hence the scale factor is 12.34/10 = 1.234, so the run time for a job that ran on a L5530 is multiplied by 1.234 to make it correct for sending into APEL.
CREAM/Torque
CREAM/Torque configurations typically make use of YAIM. Following is the appropriate section of the report that we need to use.
Cluster: TORQUE_BATCH_HAMMER Set label, Nodetype, Number, Slots, Slot HS06, HS06
25p2, E5-2630, 10, 23, 11.28, 2594.40
Cluster properties: HS06 : 2594 Physical CPUs : 20 Logical CPUs (slots): 230 Cores: 11.500 Benchmark: 11.280 CE_SI00: 2820 CPUScalingReferenceSI00: 2500.000
This is the information that needs to be put in the site-info.def YAIM config for our CE, as per the following mappings:
CE_PHYSCPU=20 CE_LOGCPU=230 CE_CAPABILITY="CPUScalingReferenceSI00=2500 Share=atlas:XX Share=lhcb:YY glexec" CE_SI00=2820 CE_OTHERDESCR=Cores=11.5,Benchmark=11.28-HEP-SPEC06
That's a straightforward mapping from the report to the YAIM variables. Run YAIM and your CE will publish the right values.
If you want to do it by hand, the Publishing Tutorial[8] lays out the steps in detail. To summarise: Count all the slots in all nodes in the cluster and put it in CE_LOGCPU. Count all the cpus in all the nodes in the cluster and put it in CE_PHYSCPU. The CPUScalingReferenceSI00 component of CE_CAPABILITY is just the BASELINE HS06 times 250 to turn it into bogoSI2k. The Cores component of CE_OTHERDESCR is just CE_LOGCPU / CE_PHYSCPU. The Benchmark component is the average HS06 benchmark strength of a single slot (i.e. total HS06/ logical cpus), tagged with -HEP-SPEC06. The CE_SI00 attribute is Benchmark, but expressed in SI2k as an integer by multiplying it by 250 and rounding it.
Note: the YAIM mapping above would be good for a site with one CE, so the only trick left is to describe how we deal with the case where we have multiple, e.g. two, CEs talking to the same Torque server. In this case, it would be arithmetically correct to set the logical and physical cpu counts in one CE, and set them to zero in the other, else double counting would occur. Unfortunately this raises divide by zero errors elsewhere. To workaround that, we set set the logical and physical cpu counts to 1 in one CE, and set them to the “count – 1” in the other CE. This kludge gives the correct arithmetic while avoiding the zero division, so everyone is happy. You can adjust this technique for any amount of CEs.
ARC/Condor
Most of this comes from the Example Build of an ARC/Condor Cluster[9], section “Notes on HEPSPEC Publishing Parameters”. In ARC/Condor, the publishing settings are put directly in the /etc/arc.conf config file; no YAIM is used, so the changes can be simply rolled out in (say) Puppet or whatever you use to control your configuration.
The basic process for publishing the HEPSPEC in an ARC/Condor set-up is similar to that used for CREAM/Torque, described above and in the Publishing_tutorial[8] and in an equivalent explanation[11]. However, the Publishing_tutorial describes a situation where YAIM is used to convert and transfer the information into a CREAM/Torque BDII. In the case of ARC/Condor, the same data has to be transposed into the /etc/arc.conf configuration file so that the ARC BDII can access and publish the values. The following table shows how to map the YAIM values referenced in the tutorial to the relevant configuration settings in the ARC system.
| Description | YAIM variable | ARC Conf Section | Example ARC Variable | Notes |
| Total physical cpus in cluster | CE_PHYSCPU=114 | N/A | N/A | No equivalent in ARC |
| Total slots/cores/logical-cpus/threads in cluster | CE_LOGCPU=652 | [cluster] and [queue/grid] | totalcpus=652 | Only 1 queue; same in both sections |
| Accounting scaling (option 1) | CE_CAPABILITY="CPUScalingReferenceSI00=2500 ... | [grid-manager] | jobreport_options="... benchmark_value: 2500.00" | Provides the reference for accounting with JURA |
| Accounting scaling (Option 2) | CE_CAPABILITY="CPUScalingReferenceSI00=2500 ... | [grid-manager] | cpu_scaling_reference_si00="2500" (alt. benchmark="SPECINT2000 2500") | Provides the reference for accounting with APEL Client |
| Power of 1 logical cpu, in HEPSPEC06 * 250 (bogoSI00) | CE_SI00 | [infosys/glue12] | NA | See YAIM docs; equivalent to benchmark * 250 |
| Cores: the average slots in a physical cpu | CE_OTHERDESCR=Cores=n.n, ... | [infosys/glue12] | processor_other_description="Cores=5.72 ..." | YAIM var shared with benchmark (below) |
| Benchmark: The scaled power of a single core/logical-cpu/unislot/thread ... | CE_OTHERDESCR=...., Benchmark=11.88-HEP-SPEC06 | [infosys/glue12] | processor_other_description="...,Benchmark=11.88-HEP-SPEC06" | YAIM var was shared with Cores (above) |
VAC
The VAC cluster is just a headless collection of nodes. Nonetheless, we treat it as just another cluster for these purposes. As per ARC/Condor, no YAIM support is available - the required settings are just put in the config file, direct from the report. Since a VAC cluster has no BDII information system, as such, the publishing requirements are very simple. The following is written up in the VAC documentation[12], which must be read to form a complete picture of VAC functionality.
VAC nodes independently contact the central APEL system to send their accounting data over. The interesting parameter, in the context of benchmarking, is the hs06_per_cpu parameter in vac.conf, which is set to the HS06 value of the node type when running the expected maximum load. VM overhead is considered to be almost negligible. There are several other VAC parameters needed to connect to APEL, but these are outside the scope of this document, please see the VAC documentation.
Conclusions
We've considered what benchmarking is, how to do it, and some of its limitations. The graphs give an idea of how CPU performance tails off as slots approaches hyper-threads, and how this can be used to maximise throughput and optimise the memory per job at the same time.
We've discussed how to use the output of the benchmarking process in a site layout database, which we use to maintain the allocation of nodes to our varied cluster technologies on an on-going basis. The database also does the arithmetic for producing the published data, but we've shown how to do the job by hand, as well. Finally, we discussed how the information feeds into the publishing systems of various clustering technologies, and briefly mentioned a test that can show that some of this data is correct.
We hope this is useful for other sites, and that it helps us to build a common view on how this should be done.
Documents
[1] Hepix Benchmark Site: http://w3.hepix.org/benchmarks [2] The GridPP HEPSPEC06 Table: https://www.gridpp.ac.uk/wiki/HEPSPEC06 [3] John Gordon's notes on benchmarking: http://indico.cern.ch/event/63028/session/2/attachments/1006732/1432188/Gordon-benchmarking.pptx [4] Our custom notes on the modified script: http://hep.ph.liv.ac.uk/~sjones/gpp37/hepspeccing [5] SPEC06: https://www.spec.org/cpu2006/ [6] HS06 instructions: http://w3.hepix.org/benchmarking/how_to_run_hs06.html [8] Publishing Tutorial: https://www.gridpp.ac.uk/wiki/Publishing_tutorial [9] Example_Build_of_an_ARC/Condor_Cluster: https://www.gridpp.ac.uk/wiki/Example_Build_of_an_ARC/Condor_Cluster [11] Equivalent explanation: http://northgrid-tech.blogspot.co.uk/2010/04/scaling-capacity-publishing-and.html [12] VAC Documentation: https://www.gridpp.ac.uk/vac/